Apa itu Machine Learning?
Apa itu Machine Learning ?
Jadi apa sebenarnya “pembelajaran mesin” itu? ML sebenarnya membahas banyak hal. Bidang ini cukup luas dan berkembang pesat.
Menurut salah satu definisi :
Pembelajaran mesin adalah bidang studi yang memberi komputer kemampuan untuk belajar tanpa secara eksplisit diprogram
Contoh masalah pembelajaran mesin termasuk apa nilai pasar dari rumah ini, apakah pelanggan ini akan churn? film apa yang tepat untuk orang ini dst, Semua masalah ini adalah target yang sangat baik untuk ML, dan faktanya ML telah diterapkan untuk masing-masing hal diatas dengan baik.
ML memecahkan masalah yang tidak dapat diselesaikan hanya dengan cara numerik.
Terdapat dua mekanisme pembelajaran dalam machine learning, yaitu supervised learning (pembelajaran yang diawasi) dan unsupervised learning (tidak diawasi):
- Supervised learning: Program ini “dilatih” dengan seperangkat “contoh pelatihan” dimana pelatihan yang diberikan telah diinfokan hasil yang valid untuk pelatihan tesebut. Komputer akan belajar menemukan pola/rumusan dari banyak training untuk mendapatkan hasil sesuai hasil yang diinfokan. Selanjutnya ketika diberikan data baru komputer bisa memprediksi hasil yang valid.
- Unsupervised learning: Program ini diberikan banyak data dan harus menemukan pola dan hubungan di dalamnya tanpa diinformasikan traning set tersebut hasil valid nya seperti apa.
Supervised Learning
Dalam supervised learning, tujuan utamanya adalah untuk mengembangkan fungsi prediktor h(x)(kadang-kadang disebut “hipotesis”). “Proses Belajar” menggunakan algoritma matematika untuk mengoptimalkan fungsi ini sehingga, diberikan data input xtentang domain tertentu (katakanlah, jumlah kamar), itu akan secara akurat memprediksi beberapa nilai h(x)(katakanlah, harga pasar rumah).
Dalam prakteknya, xhampir selalu mewakili beberapa data. Jadi, misalnya, prediktor harga perumahan mungkin tidak hanya mengambil gambar persegi ( x1) tetapi juga jumlah kamar tidur ( x2), jumlah kamar mandi ( x3), jumlah lantai ( x4), tahun dibangun ( x5), kode pos ( x6), dan sebagainya. Menentukan input mana yang akan digunakan dalam proses pembelajaran adalah bagian penting dari desain ML, namun, untuk memudahkan penjelasan disini maka nilai input tunggal digunakan.
Jadi katakanlah prediktor sederhana kita sebagai berikut:
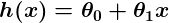
di mana 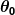 dan
dan 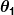 merupakan konstanta. Tujuan kita adalah untuk menemukan nilai-nilai yang terbaik dan untuk membuat prediktor kita sebaik mungkin.
merupakan konstanta. Tujuan kita adalah untuk menemukan nilai-nilai yang terbaik dan untuk membuat prediktor kita sebaik mungkin.
Mengoptimalkan prediktor h(x)dilakukan menggunakan contoh-contoh pelatihan (training set) . Untuk setiap contoh pelatihan, kita memiliki nilai input x_train, dan output yyang sesuai, yang telah diketahui sebelumnya. Untuk setiap contoh, akan menemukan perbedaan antara nilai yang diketahui, y, dan nilai prediksi h(x_train). Dengan contoh pelatihan yang cukup, perbedaan ini memberi kita feedback untuk mengukur “error” dari h(x). Kita kemudian dapat mengoptimalkan h(x)dengan mengutak-atik nilai dan membuatnya “sedikit berkurang kesalahannya”. Proses ini berulang-ulang sampai sistem telah terkonvergensi pada nilai terbaik untuk dan . Dengan cara ini, prediktor menjadi terlatih, dan siap melakukan prediksi.
Contoh Machine Learning
Sebagai ilustrasi kita akan gunakan contoh masalah sederhana di artikel ini, namun di kasus dunia nyata, masalahnya jauh lebih kompleks. Pada contoh ini kita dapat menggambarkan paling banyak data tiga dimensi, tetapi masalah ML umumnya berurusan dengan data dengan jutaan dimensi, dan fungsi prediktor yang sangat kompleks. Dalam hal ini ML memecahkan masalah yang tidak dapat diselesaikan hanya dengan cara numerik.
Dengan itu, mari kita lihat contoh sederhana. Katakanlah kami memiliki data pelatihan berikut, di mana karyawan perusahaan telah menilai kepuasan mereka pada skala 1 hingga 100:
Pertama, perhatikan bahwa datanya sedikit mengandung noise. Artinya, sementara kita dapat melihat bahwa ada pola diatas(yaitu kepuasan karyawan cenderung naik ketika gaji naik), itu tidak semua pas pada garis lurus. Hal seperti ini akan selalu terjadi dengan kasus di dunia nyata (dan kita tentu saja ingin melatih aplikasi kita menggunakan data dunia nyata!). Jadi bagaimana kita bisa melatih aplikasi ML untuk memprediksi dengan sempurna tingkat kepuasan karyawan? Jawabannya, tentu saja, kita tidak bisa. Tujuan ML tidak pernah membuat tebakan “sempurna”, karena di ML tidak memprediksi hal semacam itu. Tujuannya adalah untuk membuat tebakan yang cukup bagus untuk bisa berguna.
Machine Learning sangat bergantung pada statistik. Sebagai contoh, ketika kita melatih mesin kita untuk belajar, kita harus memberikan sampel acak yang signifikan secara statistik sebagai data pelatihan. Jika set pelatihan tidak acak, kita memiliki risiko yang ada didunia nyata tidak masuk dalam pola pembelajaran mesin . Dan jika set pelatihan terlalu kecil, maka ML tidak akan cukup belajar dan bahkan dapat mencapai kesimpulan yang tidak akurat. Misalnya, mencoba memprediksi pola kepuasan perusahaan berdasarkan data dari top manajemen saja kemungkinan akan rawan kesalahan.
Dengan pemahaman ini, mari berikan data kepada mesin kita yang telah diberikan di atas dan agar ML mempelajarinya. Pertama kita harus menginisialisasi prediktor kita h(x)dengan beberapa nilai yang masuk akal dan . Sekarang prediktor kami terlihat seperti ini ketika ditempatkan di atas perangkat pelatihan kita:
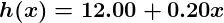

Data Example
Jika kami meminta prediktor ini untuk kepuasan karyawan yang menghasilkan $ 60.000, itu akan memprediksi peringkat 27:
Sudah jelas bahwa ini adalah tebakan yang sangat salah dan bahwa mesin ini belum memiliki prediktor yang baik.
Jadi sekarang, mari kita berikan prediktor ini semua nilai gaji dari kumpulan pelatihan kita, dan menghitung perbedaan antara prediksi peringkat kepuasan yang dihasilkan dengan peringkat kepuasan sebenarnya dari karyawan yang sesuai. Jika kita melakukan sedikit perhitungan matematika, kita dapat menghitung, dengan kepastian yang sangat tinggi, bahwa nilai 13,12 untuk dan 0,61 akan memberi kita prediktor yang lebih baik.
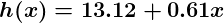
Dan jika kita mengulangi proses ini, katakanlah 1500 kali, prediktor kita akan berakhir seperti ini:
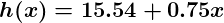
Pada titik ini, jika kita mengulangi prosesnya, kita akan menemukan itu dan tidak akan berubah dengan nilai yang berarti lagi dan dengan demikian kita melihat bahwa sistem telah terkonvergensi. Jika kita tidak membuat kesalahan, ini berarti kita telah menemukan prediktor yang optimal. Oleh karena itu, jika sekarang kita meminta mesin lagi untuk menilai kepuasan karyawan yang penghasilannya $ 60k, maka akan memprediksi peringkat sekitar 60.
Regresi Machine Learning: Catatan Kompleksitas
Contoh di atas secara teknis merupakan penyederhanaan dari regresi linier univariat , yang pada kenyataannya dapat diselesaikan dengan membuat persamaan matematika sederhana dan tidak perlu melakukan proses “tuning” ini sama sekali. Namun, coba pertimbangkan prediktor yang terlihat seperti ini:
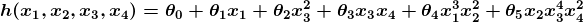
Fungsi ini membutuhkan input dalam empat dimensi dan memiliki beragam variable polinomial. Mendapatkan persamaan normal untuk fungsi ini adalah sangat sulit. Bahkan, banyak masalah pembelajaran mesin mengambil ribuan atau bahkan jutaan dimensi data untuk membangun prediksi menggunakan ratusan koefisien. Memprediksi seperti apa iklim dalam lima puluh tahun, adalah contoh dari masalah rumit tersebut.
Untungnya, pendekatan iteratif yang dilakukan oleh sistem ML cukup tangguh untuk menghadapi kompleksitas seperti itu. Alih-alih menggunakan brute force, sistem pembelajaran mesin “memiliki arah” untuk mendapatkan jawabannya. Meskipun ini tidak berarti bahwa ML dapat menyelesaikan semua masalah yang sangat kompleks,ML meberikan alat yang sangat fleksibel.
Gradient Descent – Meminimalkan “Kesalahan”
Mari kita lihat lebih dekat bagaimana cara kerja proses iteratif ini. Dalam contoh di atas, bagaimana kita memastikan dan menjadi lebih baik dengan setiap langkah, dan tidak lebih buruk? Jawabannya terletak pada “pengukuran kesalahan” yang disinggung sebelumnya, bersama dengan sedikit kalkulus.
Ukuran kesalahan dikenal sebagai cost function (alias, fungsi biaya ) 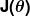 ,. Masukan
,. Masukan 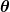 mewakili semua koefisien yang kita gunakan dalam prediktor kita. Jadi dalam kasus kita , benar-benar pasangan dan .
mewakili semua koefisien yang kita gunakan dalam prediktor kita. Jadi dalam kasus kita , benar-benar pasangan dan . 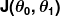 memberi kita pengukuran matematis tentang bagaimana salahnya prediktor kita ketika menggunakan nilai dan .
memberi kita pengukuran matematis tentang bagaimana salahnya prediktor kita ketika menggunakan nilai dan .
Pilihan cost function adalah bagian penting dari program ML. Dalam konteks yang berbeda, menjadi “salah” dapat berarti hal-hal yang sangat berbeda. Dalam contoh kepuasan karyawan kami, standar yang ditetapkan dengan baik adalah fungsi linear least square
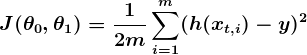
Dengan least square, penalti untuk tebakan buruk naik secara kuadratik dengan perbedaan antara tebakan dan jawaban yang benar, sehingga bertindak sebagai ukuran kesalahan yang sangat “strict “. Fungsi biaya menghitung penalti rata-rata terhadap semua data pelatihan.
Jadi sekarang kita melihat bahwa tujuan kita adalah menemukan dan untuk prediktor h(x)kami sehingga fungsi biaya kita sekecil mungkin. Kita menggunakan kalkulus untuk menyelesaikan hal ini.
Pertimbangkan plot fungsi biaya berikut untuk suatu case Machine Learning:
Di sini kita dapat melihat biaya yang terkait dengan nilai dan berbeda . Kita dapat melihat grafik memiliki sedikit bentuk. Bagian bawah mangkuk mewakili biaya terendah yang dapat diberikan oleh prediktor kami berdasarkan data pelatihan yang diberikan. Tujuannya adalah untuk “menuruni bukit”, dan menemukan dan sesuai dengan titik ini.
Di sinilah kalkulus berguna dalam tutorial pembelajaran mesin ini. Pada dasarnya apa yang kita lakukan adalah mengambil gradien , yang merupakan pasangan derivatif (satu berakhir dan satu berakhir ). Gradien akan berbeda untuk setiap nilai yang berbeda dan , dan memberi tahu kita apa “kemiringan bukit itu” dan, khususnya, “jalan mana yang turun”, untuk s tertentu . Sebagai contoh, ketika kita memasukkan nilai-nilai kita saat ini ke dalam gradien, mungkin memberitahu kita bahwa menambahkan sedikit dan mengurangi sedikit dari akan membawa kita ke arah dasar. Karena itu, kita tambahkan sedikit, dan kurangi sedikit dari , Kita telah menyelesaikan satu putaran algoritma pembelajaran kita . Prediktor kita yang diperbarui, h (x) = + x, akan menghasilkan prediksi yang lebih baik dari sebelumnya. Mesin kita sekarang sedikit lebih pintar.
Proses bergantian antara menghitung gradien saat ini, dan memperbarui s dari hasil, dikenal sebagai gradien descent.
Itu mencakup teori dasar yang mendasari sebagian besar sistem supervised machine learning. Tetapi konsep-konsep dasar dapat diterapkan dalam berbagai cara yang berbeda, tergantung pada masalah yang dihadapi.
Masalah Klasifikasi dalam Pembelajaran Mesin
Dalam supervised machine learning , ada dua subkategori utama:
- Sistem pembelajaran mesin regresi: Sistem di mana nilai yang diprediksi bisa berada pada suatu angka / kontinu. Sistem ini membantu kita dengan pertanyaan tentang “Berapa banyak?” Atau “Berapa banyak?”.
- Sistem pembelajaran mesin klasifikasi: Sistem di mana kita mencari prediksi ya-atau-tidak, seperti “Apakah ini kanker?”, “Apakah kue ini memenuhi standar kualitas kami?”, Dan seterusnya.
Teori Machine Learning yang mendasari kurang lebih sama. Perbedaan utama adalah desain prediktor h(x)dan desain fungsi biaya .
Contoh kita sejauh ini fokus pada masalah regresi, jadi sekarang mari kita lihat contoh kasus klasifikasi.
Berikut adalah hasil dari pengujian pengujian kualitas kue, di mana contoh-contoh pelatihan semuanya diberi label sebagai “kue yang baik” ( y = 1) dengan warna biru atau “kue yang buruk” ( y = 0) berwarna merah.
Dalam klasifikasi, prediktor jenis regresi tidak terlalu sesuai. Yang kita inginkan adalah prediktor yang menebak di antara 0 dan 1. Dalam penggolongan kualitas kue, prediksi 1 akan mewakili dugaan yang sangat yakin bahwa cookie itu baik. Prediksi 0 mewakili keyakinan tinggi bahwa cookie itu buruk bagi industri perkuean. Nilai yang jatuh dalam rentang ini menunjukkan tingkat kepercayaan yang berbeda, jadi kita mungkin mendesain sistem kami sehingga prediksi 0.6 berarti “tipis, tapi saya akan pergi dengan ya, Anda bisa menjual kue itu,” sementara nilai persis di tengah, pada 0,5, mungkin merupakan ketidakpastian yang jelas. Ini tidak selalu tentang bagaimana kepercayaan didistribusikan dalam classifier tetapi ini adalah desain sangat umum dan berfungsi untuk tujuan ilustrasi kita.
Ternyata ada fungsi yang tepat yang mewakili perilaku ini dengan baik. Yaitu fungsi sigmoid , g(z)dan itu terlihat seperti ini:
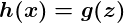
z adalah beberapa representasi input dan koefisien kita , seperti:
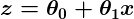
sehingga prediktor kita menjadi:
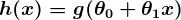
Perhatikan bahwa fungsi sigmoid mengubah output kita menjadi kisaran antara 0 dan 1.
Logika di balik desain fungsi biaya juga berbeda dalam kasus klasifikasi. Sekali lagi kita bertanya “apa artinya tebakan yg salah?” Dan kali ini aturan yang sangat baik adalah bahwa jika tebakan yang benar adalah 0 dan kami menebak 1, maka kami benar-benar dan benar-benar salah, dan sebaliknya . Karena Anda tidak bisa lebih salah daripada benar-benar salah, penalti dalam kasus ini sangat besar. Atau jika tebakan yang benar adalah 0 dan kami menebak 0, fungsi biaya kita seharusnya tidak menambahkan biaya apa pun untuk setiap kali ini terjadi. Jika tebakannya benar, tetapi kita tidak sepenuhnya yakin (misalnya y = 1, tetapi h(x) = 0.8), ini harus datang dengan biaya kecil, dan jika tebakan kita salah tetapi kami tidak sepenuhnya yakin (misalnya, y = 1tetapih(x) = 0.3), ini harus datang dengan biaya yang signifikan, tetapi tidak sebanyak jika kita sepenuhnya salah.
Perilaku ini ditangkap oleh fungsi log, sehingga:
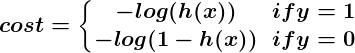
Sekali lagi, fungsi biaya memberi kita biaya rata-rata atas semua contoh pelatihan kita.
Jadi di sini kita telah menjelaskan bagaimana prediktor h(x)dan fungsi biaya berbeda antara regresi dan klasifikasi, tetapi penurunan gradien masih berfungsi dengan baik.
Prediktor klasifikasi dapat divisualisasikan dengan menggambar garis batas; yaitu, penghalang di mana prediksi berubah dari “ya” (prediksi lebih besar dari 0,5) menjadi “tidak” (prediksi kurang dari 0,5). Dengan sistem yang dirancang dengan baik, data kue kita dapat menghasilkan batas klasifikasi yang terlihat seperti ini:
Pengantar Jaringan Saraf (Neural Networks)
Tidak ada diskusi tentang Machine Learning akan lengkap tanpa setidaknya menyinggung neural networks/ jaringan saraf . Tidak hanya jaring saraf menawarkan alat yang sangat kuat untuk memecahkan masalah yang sangat sulit, tetapi ia juga memberikan petunjuk menarik pada cara kerja otak kita sendiri, dan kemungkinan menarik untuk satu hari menciptakan mesin yang benar-benar cerdas.
Jaringan syaraf sangat cocok untuk model pembelajaran mesin di mana jumlah inputnya sangat besar. Biaya komputasi untuk menangani masalah seperti itu terlalu besar untuk jenis sistem yang telah kita diskusikan di atas. Ternyata, jaringan saraf dapat secara efektif dibuat menggunakan teknik yang sangat mirip dengan gradien descent pada prinsipnya.
Pembelajaran Mesin Tanpa pengawasan (unsupervised)
Pembelajaran mesin tanpa pengawasan biasanya ditugaskan untuk menemukan hubungan dalam data. Tidak ada contoh pelatihan yang digunakan dalam proses ini. Sebagai gantinya, sistem diberikan satu set data dan ditugasi dengan menemukan pola dan korelasi di dalamnya. Contoh yang baik adalah mengidentifikasi kelompok teman dekat dalam data jejaring sosial.
Algoritma Machine Learning yang digunakan untuk melakukan ini sangat berbeda dari yang digunakan untuk pembelajaran yang diawasi, dan topiknya mendapat pos sendiri. Namun, untuk sesuatu untuk diketahui sementara ini, lihatlah clustering algorithm seperti k-means,
Kesimpulan
Kita telah membahas banyak dari teori dasar yang mendasari bidang Machine Learning di sini, tetapi tentu saja, ini baru permukaannya saja.
Perlu diingat bahwa untuk benar-benar menerapkan teori yang terkandung dalam pengantar ini ke contoh pembelajaran mesin kehidupan nyata, pemahaman yang jauh lebih mendalam tentang topik yang dibahas di sini diperlukan. Ada banyak seluk-beluk di ML, dan banyak cara untuk terkecoh oleh apa yang tampaknya merupakan mesin pemikiran yang sempurna. Hampir setiap bagian dari teori dasar dapat dicoba dan diubah tanpa henti, dan hasilnya seringkali menarik. Banyak yang tumbuh menjadi bidang studi baru yang lebih cocok untuk masalah tertentu.
Jelas, Machine Learning adalah alat yang sangat powerful. Dimasa depan, akan menjanjikan untuk membantu menyelesaikan beberapa masalah kami yang paling mendesak, serta membuka dunia peluang baru. Permintaan machine learning engineer hanya akan terus tumbuh, menawarkan kesempatan yang luar biasa untuk menjadi bagian dari sesuatu yang besar.